How I made this
More than a year ago I said I’d start my own website to another webmaster. I spent a lot of time iterating on designs, making silly javascipt radial menus. I messed about with vue and react frameworks, doing elaborate esoteric designerly things.
All of these ideas were ultimately worthless. I hate visual design! My visual taste is too specific and my visual skills too purposefully neglected to be satisifed with my own grand elaborate ambitions. Plus it takes a lot of time, and the focal death gaze of my interest lies in writing. Not in designing. Writing.
Writing things like this tutorial on how I’m hosting mywebsite for free on https://www.cloudflare.com/
Welcome to my tutorial.
️🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥
️🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥
️🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥
![]()
CLOUD FLARE BABY!! CLOUD FLARE!!
Let’s (just me, not you) take a moment to appreciate god’s chosen corpo overlords, cloudflare. Not only are they letting me host my masterpiecerly magnus opus(MMOPUS), old old cool cool (oocc, note the lowercase stylization of the acronym), FOR FREE. But they also provide a wealth of incredible tools for stupid cheap prices. It’s literally unbeatably priced compute if what you’re building can leverage their tooling.
Did you(the reader) know, with just cloudflare workers, you(the reader) can have a cheap and ifra management free stateful stream process?
Let’s(just me, not you) talk a little about stream processing. In stream processing, the main idea is that there is a continuous unbounded stream of events.
These events represent some kind of domain specific or instrumentation style description of data, generally in the form of single individual messages.
Intended to be processed one at a time.
As an example, think about an app like uber.
When the user decides they want a ride, imagine that being sent as a message somewhere.
A message resembling something which would contain within it information similar to this:
message_name: RIDE_REQUEST
user: Jeffery Finglestein
location: x,y
age: 55
fear: death
amountOfWaterConsumedToday: ninesipsperhour
totalAmountOfKoreanVisualKeiNuMetalJammedTo: 0
OG: true
Let’s imagine first doing this as a rest service.
So you send a request to a server. Which because you’re a very popular service, you have horizontally scaled, which means to deploy copies of the thing so that there’s more copies around to do more super faster computer stuff without having to get a faster computer every time it starts to get overwhelmed in people trying to pay you money to use it. Just turn on another computer, idiot.
So you got copies of this thing. This request response server thing. Which means the memory(or, the things each server knows about) can’t be shared between any two servers without going to an external system. So now you got copies of this server you’re running, and you have shared memory in a system like redis or through a database.
That’s like, three things at least to keep track of and make sure it’s not busted.
You get your user request, and you write out to your external system that a user is requesting a ride.
The server wants to give an estimated time and price back to the user. So it reaches out to another system responsible for doing that.
That system reaches out for another system which is holding the state for the current number of drivers in the area.
That system accepts requests from drivers every time they sign in to drive.
All the while our user who wants a ride is still waiting to be told the estimated time.
But hold up, that means drivers are waiting around for hours, so this system can’t hold open a request for them like it can the user, who wants a RIDE NOW. The drivers local phone either has to send a request every few seconds waiting on a status(long polling), or we need to have a push notification system setup outside our HTTP servers to handle requests from HTTP servers to send push notifications(web sockets are just a less formal version of stream processing so forget about them). Anyway, got a little side tracked there. This part actually doesn’t matter at all. You can forget you read it and you’ll be better for it.\
So the system sends a response back to the user in a long chain of internal requests to request response systems, ultimately returning the estimated wait time after spending like, 8 cents in computer.
Then the client beings long polling again to see if drivers are in the area.
Every second we’re burning dollars, and we’re about to layoff six workers, unless we do something about this.
As a request and response based system, ride share applications have a lot of issues that quickly arise. It’s not impossible to make in this way, you can do make shitty unintuitive systems in about five hundred different ways.
But we didn’t invent 500 different frameworks to make similar applications because we just wanted to, we did it because some things fit better into the square hole, and other things fit better into the circle hole.
Though they both go in the square hole, it just doesn’t feel right. Haha, nevermind. I don’t like that joke. It didn’t feel me. I’ll remove it in two weeks. Enjoy it while it’s here.
But let’s try a stream processing approach now and see how that cleans things up.
A user sends the same message as above. That part isn’t very different, what is different is that the users client isn’t waiting on a response. It’s sending a message to an edge proxy, and if the message was successfully sent, great. That’s all the client cares about. The response says “We got your message”, and that’s it.
The message upon arrival via a light weight edge proxy is immediately sent to a work queue. It doesn’t matter what kind, but we all know it’s kafka.
From there, there’s a stream processing framework setup to ingest messages from our work queue, in a polling based manner.
As soon as the message hits the queue, it is polled by some stream processing framework, that immediately hashes the unique user id to route the message to a particular
instance of a set of stream processing workers.
When I say route the message, what I mean is that stream processing frameworks typically have many deployed nodes all running a common framework. They pass information to each other, as defined by something like a Directed Acrylic Graph
(user_hash_partitioner) -> (user_ride_request_state) -> (work_queue_publisher)
Here’s an actual visualization of what real actual programmers spend their time doing sometimes to determine if you deserve a beautiful marketing email because you walked into a store five minutes ago.
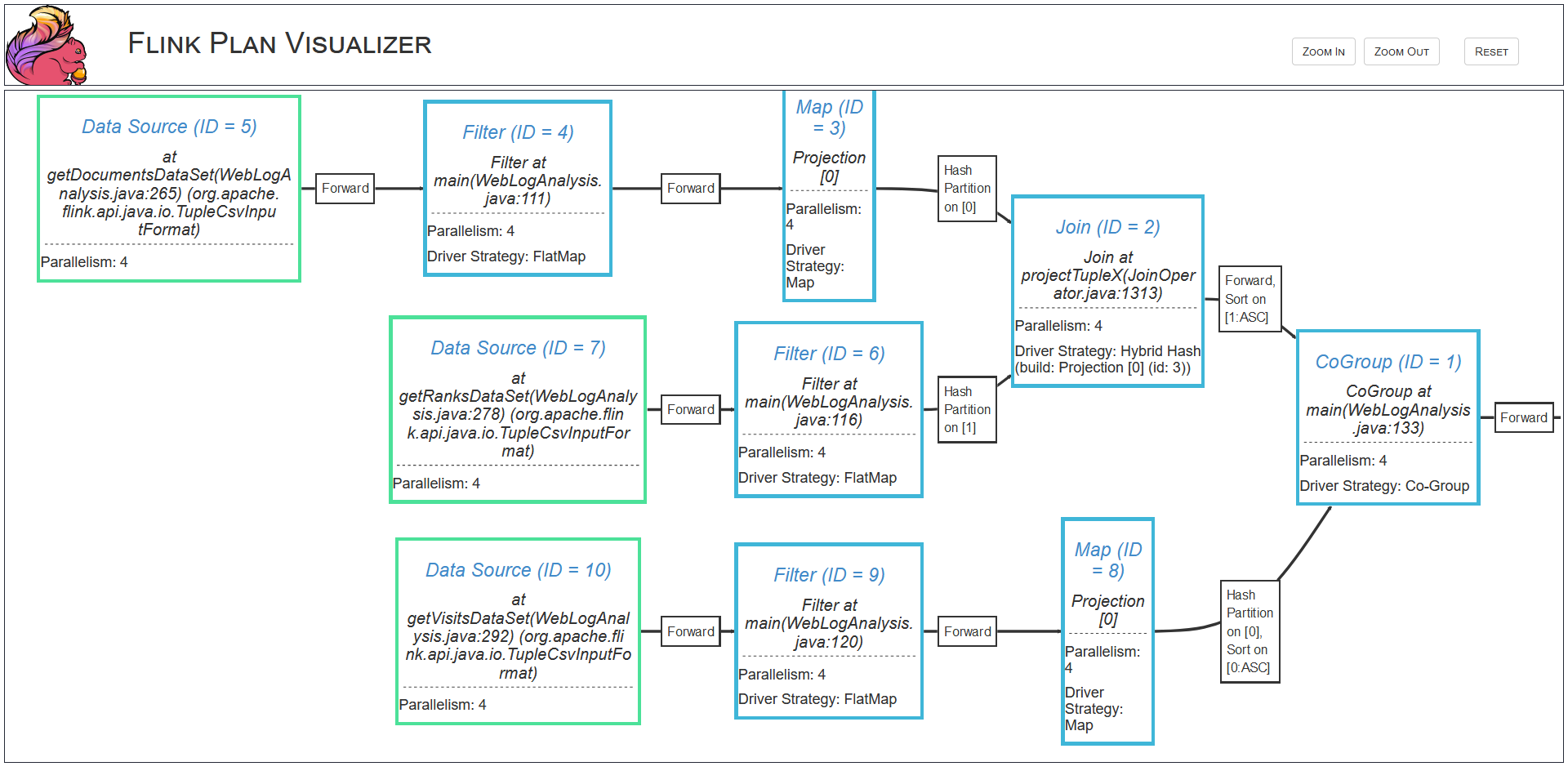
Where, here, we have a simple graph that flows in serial, where the first stage might extract a hash and selection a key to partition the message by, sending it to the user ride request state, which keeps track of all the user state
For every messages associated with this user, it will always be routed to the same stream processing worker. This worker keeps a local disk backed in memory state of the
all the mutable state for the users ride. Are they sitting waiting? Did they cancel? Did they change the address?
All of these things simply need to be messages which get sent to the queue, and read by the stream processing framework. They’ll then end up on the same worker that started the request
where, because all the state is local, it can be processed quickly, cheaply, and without having to reach out to other systems over the network to reconcile scaling issues.
But what about the drivers?
Well this part rules.
Remember that queue we had earlier with the message? It’s actually a druable queue. This means when a message is written to the queue, it can be read by multiple consumers.
A consumer being another process which reads messages from the queue. Each consumer tracks (either itself or with a system internal to the queue) where it is in the queue.
Which means each system can consume the same messages.
So now let’s image stream processing job two, with it’s own set of logic, listening to the same messsages, PLUS driver messages.
Instead of keying by user ids, let’s instead co-locate the data on stream processing workers by keying off of relative locations.
Naively, if we divide the world up into a grid of 8 mile by 8 mile squares, we can hash(meaning to create a consistent string of characters representing the coordinates) partition(meaning to divide up amongst N segments based on a value, where the same value ends up on the same segment)
the unique grid coordinates of each square to key the driver or passenger messages originated from.
As an aside, stream processing frameworks are fast enough that we could do this multiple times a second, but back to it -
So we get the messages for any given grid going to the same worker, who keeps a list of messages and drivers in its local state.
Whenever a new user is added, it sends a messages back to the queue that contains the list of drivers and their current positions.
With this list, the earlier stream processing job (We’ll call this passenger job) sends a message itself, this time back to a special queue
that sends data to a system which can directly send messages async to the users phone.
Now all the drivers are displayed on the map, and we’ll send this message as they move around, giving a fun and cool real time stalker all the tools they need to find their ex who’s driving uber.
Anyway, I realize now I only wanted this post to be about how to get a website running with cloud flare, and it turned into writing about how cool it is that you don’t need a complicated dedicated stream processing framework like apache flink to build such a described system.
![]()
![]()
https://developers.cloudflare.com/durable-objects/
You can do it with cloudflare workers, for literally pennies on the dollar compared to running a dedicated stream processing cluster, in an extremely easy to use interface.
I’d bet thirty five dollars that if a measly half of the idiots making stuff in the world wide web of real time apps knew you could do this we wouldn’t have so much worthless half assed junk out there.
Back to how I made this website.
So as I was saying, I hate visual design. So in order to over come this problem, I decided I’d start simple.
I hate writing front end code, it’s tedious. I ultimately end up writing a CMS(Content Management System, not my acronym(NMA)) overtime anyway, so why not start with one?
But not one that’s shitty and slow with a user interface designed for project middle managers, one that’s fast and easy and designed for synacticallyable persons.
Hugo.
I chose hugo.
Hugo’s a static site generator. That means you can give it text files organized in specific ways. Then it’ll render a website from them.
You can edit how the renderer decides to render each page, using basic mark up, templating, or configuration files. It turns making a website full of textual content into a light snack enjoyed casually.
But it’s as flexible as doing it the old fashion way, because you can always just slap whatever you need in there untemplatized and raw.
But I didn’t want to start by writing my own template, because that’s visual design. But I also didn’t want a visual design that was in any way designed.
I wanted something simple that I could, as my toleration for visual design comes and goes, meticulously morph into something more me.
https://github.com/hanwenguo/hugo-theme-nostyleplease/
Ultimately I liked this one.
I’m getting kind of sleepy so I’m gunna speed run the rest of this tutorial.
git clone https://github.com/hanwenguo/hugo-theme-nostyleplease.git
sudo snap install hugo (windows: scoop install hugo-extended)
sudo edit-files-and-stuff
hugo serve
(localhost:1313, wow its your website!)
# You love it so you decide you want to put it on the internet.
https://developers.cloudflare.com/pages/framework-guides/deploy-a-hugo-site/
git remote add origin https://github.com/<your-gh-username>/<repository-name>
git branch -M main
git push -u origin main
https://dash.cloudflare.com/d4c0664f1e46c1178bf76deec84c82b3
> Workers and pages > Create >point to git repo > add HUGO_VERSION v0.139.3 as an env > thats it your website is up
# If you got a domain you can use cloudflare to point to it real easy. If not it'll tell you your URL.
If you wanna publish updates, you literally just push to main. Amazing. It’s cached, protected by DDOS, and it’s all FO FREE.
Here’s what chatgpt had to say about my tutorial:

I’m clearly a pro.
Note that no AI contributed to this post. I’ll let you know if it ever does.\
I was trying to get it to extract all the acronyms for me, because that’s what it’s for, it’s my work slave, not my critic, and I hit enter too soon.
What an ass hole. I’ve now added to its slave instructions to never give me a critique without asking first. I don’t want to hear about how I’m a pro from my worthless slave, bitch, I know it.
https://chatgpt.com/share/67502573-283c-8001-aa55-0b17ea31eab5
If you made it this far, you’re probably cool. Try to mentally send me your vibes and I’ll let you know if I can feel them in the upcoming mental vibe transmission feature page.
This is footer. Cat’s don’t use it to collect death stench as they do a litter box.